Java内存模型简介
Java内存模型(Java Memory Model)不是一个好理解的概念,这篇博客尝试对java内存模型做一个简单的介绍,重点说明为什么需要java内存模型以及java内存模型是什么
硬件的内存架构(Hardware Memory Architecture)
所有软件都是运行在硬件之上的,解释java内存模型前,我们先了解一下硬件的内存架构
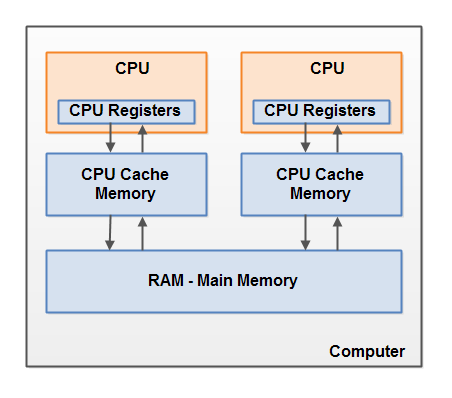
一台计算机可能有2个或者更多cpu,每个cpu包含了一些列的寄存器和多级缓存,所有的cpu共享一个主内存(RAM)。任何时候一个cpu可以运行一个线程,多个cpu可以同时执行多个线程。
Java内存
栈(Stack)和堆(Heap)
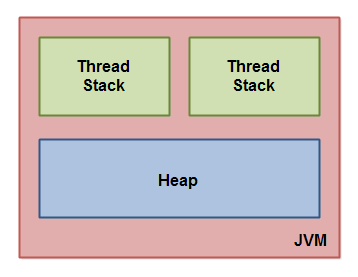
Java虚拟机(JVM)将内存分为桟和堆,每个在java虚拟机上运行的线程都有自己的栈,线程栈包含了线程运行到目前调用过的所有方法和这些方法的局部变量。所有基本类型(boolean, byte, short, char, int, long, float, double )的局部变量,栈上完整保存该基本类型;而对象类型的局部变量,栈上仅保存对象的引用,对象本身(包括对象的所有成员)存在堆上。
一个线程只能访问自己的栈,但对于栈上对象类型变量,可以通过引用访问到堆上的对象本身。反过来说,堆上的对象(包括对象的成员)能够被所有持有该对象引用的线程访问到。
例子
public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}
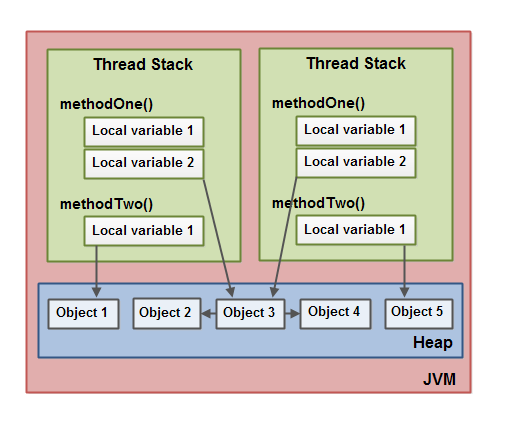
如图所示,每个线程都有自己独立的栈,栈上有methoneOne()和methodTwo(), methodOne()中的基本类型的局部变量(localVariable1)完全存在栈中,localVariable2则只有一个引用,对象本身(MySharedObject.sharedInstance)存在堆中,sharedInstance的成员变量也存在堆中。同理,methodTwo()的局部变量(localVariable1)是对象,对象本身也存在堆中,栈上只存了一个引用。此外我们注意到sharedInstance是MySharedObject类的静态变量,因此同时被多个线程引用,多个线程通过各自引用都可以访问sharedInstance对象。
java内存和真实硬件内存的映射
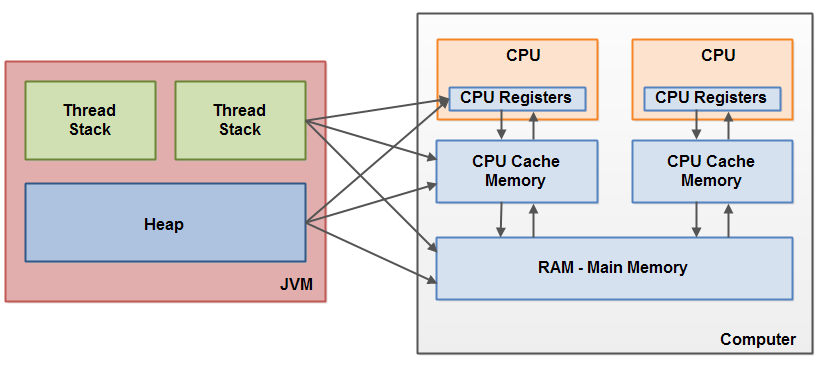
java内存和硬件内存架构是不同的:真实硬件内存架构并不区分栈(stack)和堆(heap),栈和堆都存储在主存(Main Memory)中,栈和堆的部分变量有时也可能存储在cpu的缓存或者寄存器中,如上图所示的那样。
java 内存模型(Java Memory Model)
多线程情况下共享对象引发的问题
从上面的例子中可以看到,堆上的一个对象可能被多个线程同时访问,这会引起一系列问题,考虑下面一个最简单的赋值语句,假设一个线程A更新了一个变量(多个线程都能访问到的共享变量)的值
aVariable = 3
那么现在的问题是线程A更新这个变量值为3后,另一个线程B读取这个变量时,在什么时候和什么情况下会读取到这个变量的最新值?看起来这个问题的答案明显到不需要回答,可是当我们仔细考虑硬件的内存架构,cpu指令执行细节时,至少有以下几个因素会影响线程B能读取到最新值的时机:
- 线程A的赋值结果可能存储在cpu的缓存中,出于性能的考虑,缓存可能不会将最新值立刻更新到主存中
- 即使线程A的操作结果已经刷新到主存,线程B读取的结果可能仍然cpu的本地缓存中旧值
- 编译器生成的指令顺序也许和源代码上的顺序不一样
- cpu在执行指令时,可能会并行执行指令或者不按顺序执行
……
所有的这些因素都会导致了线程B读取到最新值时机的不确定性
什么是java内存模型
java线程模型正是为了帮助解决上述问题的,先看两个权威的英文定义
Java Memory Model(JMM) details how Java handles the interaction between threads and memory.
A memory model describes the relationship between variables in a program (instance fields, static fields, and array elements) and the low-level details of storing them to and retrieving them from memory in a real computer system.
把上面的两个定义综合起来,Java内存模型描述了多线程情况下,程序中变量的读和写与真实计算机内存中变量的读和写的底层细节的关系。例如,java内存模型提供了一些工具(如synchronized和volatile关键字)确保一个线程的写操作能够在确定的时机被另外一个线程读取到,且避免共享变量被多个现存同时读、写(通过锁的机制)。
当我们在单线程环境运行程序时,程序和内存的交互非常简单,至少看起来如此。程序向变量中写入值,然后之后读取这个变量时就会读取到这个值。然而真实的情况却并非这么简单,编译器、java虚拟机和硬件对我们隐藏了诸多细节。
尽管我们认为程序是按照源代码指定的顺序执行,但实际情况却不总是如此。在不影响计算结果的情况下,编译器、处理器和缓存能够自由地处理我们的程序和数据。举例来说,编译器能够生成和源代码表面顺序不一致的机器指令,能够把变量存储在寄存器而不是内存中;处理器能够并行执行指令或者不按编译器指定的顺序执行指令;缓存能够改变向主存中提交写操作的顺序。java虚拟机规定,上述提到的这些指令重排和优化都是允许的,只要执行结果保持似串行语义(as-if-serial semantics),也就是说只要在单线程环境下,指令优化后执行的结果和指令严格按照顺序执行的结果一致就可以。这些指令和内存操作重排的影响,在单线程环境看不出来,然而在多线程环境,如果不正确地使用同步保证内存的一致性、避免竞争条件(Race Condition),那么多线程的运算结果将完全不可预测。
共享对象的竞争条件和可见性
多线程环境,要想保证程序的正确性,必须注意共享对象的竞争条件和可见性
- 竞争条件(Race Condition) 这个容易理解,多个线程共享同一个变量,如果他们同时读写该变量,竞争条件就发生了,多线程环境我们必须避免竞争条件,保证同一时刻只有一个线程能够读写这个变量。
- 可见性 因为缓存和指令重排的影响,一个线程的写操作可能不能马上被另一个线程看到,多线程环境必须保证共享对象的可见性。
synchronized和volidate是解决这两个问题的工具。
synchronized关键字
synchronized关键字修饰的代码块,有如下性质
- 互斥性:同一时刻,只能有一个线程访问这个代码块
- 读屏障(read barrier):当一个线程进入这个代码块,获得锁时,会执行一个读屏障,读屏障的意思是代码块内所有的变量的本地缓存都失效,必须从主存读取最新值
- 写屏障(write barrier):当一个线程离开这个的代码块,释放锁时,会执行一个写屏障,写屏障的意思是代码块内所有的变量的修改,必须在释放锁前,被写如到主存
互斥性确保了同一时刻只能有一个线程执行这个代码块, 而读屏障和写屏障确保了后面执行的线程能够完全看到前面执行线程的修改(可见性)。注意这里的互斥性和可见性成立的前提是,多个线程synchronized是同一个对象。
volatile关键字
- 读和写都是直接对主存操作
- volatile类型变量的读写不允许和其他任何内存操作指令重排
第二点主要是为了确保volatile在下面的应用场景下合法
/*** Example of using a volatile variable as a "guard" ***/
Map configOptions;
char[] configText;
volatile boolean initialized = false;
// In Thread A
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfigOptions(configText, configOptions);
initialized = true;
// In Thread B
while (!initialized)
sleep();
// use configOptions
如果没有第二点的保证,线程B看到的configOptions对象可能没有被完全初始化
happens-before规则
为了方便程序员理解jmm中可见性的保证,java使用happens-before的概念来阐述操作之间的内存可见性,如果A操作happens-beforeB操作,那么A操作的执行结果对B操作可见,常用的happens-before规则有:
- 程序顺序规则:同一个线程中的每个操作,happens-before 于该线程中的任意后续操作
- 监视器锁(moniter)规则:对一个监视器锁的解锁,happens-before 于随后对这个监视器锁的加锁
- volatile变量规则:对一个volatile域的写,happens-before 于任意后续对这个volatile域的读
- 传递性:如果A happens- before B,且B happens-before C,那么A happens-before C
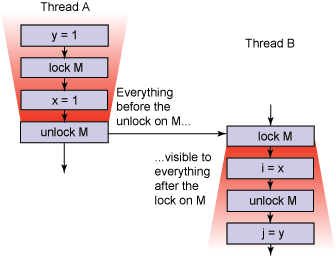
happens-before规则仅仅是阐述了java内存模型对程序员提供的可见性保证,至于如何实现这个保证,也许是通过禁止指令重排,也许是通过其他。熟练运用happens-before规则能够帮助我们分析多线程代码以及写出正确的多线程代码
撇开我们对底层细节的了解,我们可以仅从happens-before的角度分析上述volatile例子的正确性:
1.根据程序规则,在线程A中,initialized=true happends-before configOptions的初始化,也就是initialized=true时,configOptions操作结果对线程A已经完全可见,即configOptions已经完全初始化
2.根据volatile变量规则,线程A中执行initialized=true操作后,线程B后续对initialized的读操作happens-before线程A中写操作, 线程B可以读取到initialized=true
3.根据传递性规则,线程A中执行initialized=true操作后,那么线程B后续的读操作happends-before configOptions的初始化,即configOptions已经完全初始化,符合我们的预期
参考资料
- jenkov java memory model tutorial
- Brian Goetz Java Concurrency In Practise
- Java theory and practice: Fixing the Java Memory Model, part 1 - An article describing problems with the original Java memory model.
- Double-checked locking: Clever, but broken - An article describing the double-checked locking problem and the original Java memory model problems.
- Java theory and practice: Fixing the Java Memory Model, part 2 - Explains the changes JSR 133 made to the Java memory model.
- 深入理解java内存模型(一)
- The JSR-133 Cookbook for Compiler Writers
- The Java Memory Model
- Threads and memory model for C++